

Neural age : Neural Networks have revolutionized artificial vision and automatic speech recognition. This machine learning revolution is holding its promises in the voice arena. Discover how Acapela is moving forward to create the voice you need.
Our R&D lab developed Acapela DNN, a technology capable of creating personalized voices using a limited amount of speech recordings.

WHAT IS DNN?
A deep neural network (DNN) is an artificial neural network (ANN) with multiple hidden layers between the input and output layers.
Neural networks are a set of algorithms, that are designed to recognize patterns. They interpret sensory data through a kind of machine perception, labelling or clustering raw input. The patterns they recognize are numerical, into which all real-world data (images, sound, text) are produced or interpreted.
DNNs can model complex non-linear relationships using Machine Learning technologies. We use them in Text-to-Speech to learn the relationship between a set of input texts and their acoustic realizations by different speakers.
Neural TTS can be trained on a large amount of data to learn the complex patterns in human speech, such as intonation, rhythm, and emphasis. As a result, it can generate highly natural and expressive speech that closely resembles to human speech.
HOW DOES IT WORK?
Acapela DNN is trained offline using large GPU infrastructures. The system knows a lot about human speech in general but doesn’t yet know anything about a specific person’s voice and will need to hear this voice for a while before reproducing it.
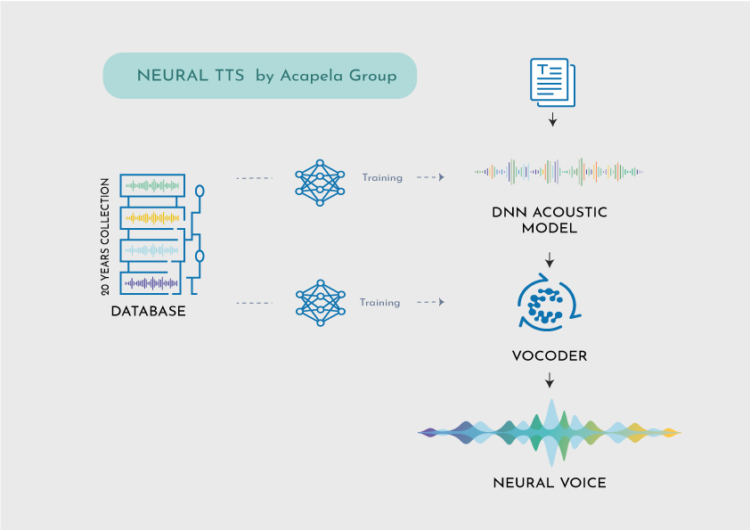
- 1st pass algorithm: Extracting ‘Voice ID’ parameters to define the digital signature (or sonority) of the vocal tract of the speaker.
- 2nd pass algorithm: Acapela DNN additional training to match the imprint of the voice with its fine grain details (accents, speaking habits, etc.)
Acapela DNN benefits from our speech expertise to model voice identities and reproduce speech, in many languages. This is much more than concatenating speech recordings from the studio like we use to do with unit selection and previous technologies, yet widely used.
In specific cases such as voice replacement for patients, Acapela DNN can work with a few minutes of speech. That is what we are achieving for patients with My-Own-Voice, a voice banking solution (innovation award in CES 2023) that allow speech-disabled individuals to keep speaking with a digital copy of their original voice, as a synthetic voice.
For a business usage, such as creating a custom voice that will for instance help drivers navigate or provide passengers real time information while commuting with an instantly recognizable voice, more recordings will be needed. Obviously, the more data there is, the more the DNN can learn from specific habits and create a voice that matches the original. Those highest quality voices allow for the generation of realistic, lifelike audio output, setting up a new standard for real-time natural interactions for an advanced user experience.
“The first results of research back in 2017 were impressive. We have worked on voice recordings of well-known people. We have also created voices for individuals who cannot speak correctly anymore due to surgery or disease. They were the first ones to speak with voices created with Acapela DNN. Creating voices based on this new technology is limitless. Acapela is now taking advantage of its unequalled asset of voice databases and expertise acquired through the years to push the boundaries of technology, allowing everyone to have a voice”, adds Remy Cadic, CEO of Acapela Group.
We work on speaker embeddings to modelize the voice. Our models capture the key features and characteristics of the spoken language. They are trained on large datasets of speech resources. Using this new technology is opening large perspectives for the TTS market and Acapela Group. Very good quality TTS voices and languages can be developed using few samples of a speaker and developing new languages and voices is becoming easier, resulting in an offer that will bring more choice and diversity for all users.
TYPE & TALK DEMO
Try the neural voices with your own words
Make the long story short
The history of TTS technology started with the very first speaking machine (1779) created by the Hungarian inventor Wolfgang von Kempelen (…) Then innovations in the early days of computing by Bell Labs in the 50’s and IBM in the 60’s started to pave the way of speech technology. Formant and diphone technologies brought major improvements before moving to the unit selection one in the 90’s.
The AI era is now designing a new digital age with machine learning capabilities and the neural voices. At Acapela Group, we are deeply involved in the technology since 30 years. Backed by our decades of expertise and valuable linguistic knowledge we aim to create voices that make the difference, resulting in a continuous evolution towards personalized lifelike speech and greater accessibility to technology and information for All.
Need more information for your voice project?
Book a demo