

L’ère neuronale: Les réseaux neuronaux ont révolutionné la vision artificielle et la reconnaissance automatique de la parole. Cette révolution tient maintenant ses promesses dans le domaine de la voix. Découvrez comment Acapela innove pour créer la voix dont vous avez besoin.
Notre laboratoire de R&D a développé Acapela DNN, une technologie capable de créer des voix personnalisées à partir d’un nombre limité d’enregistrements vocaux.

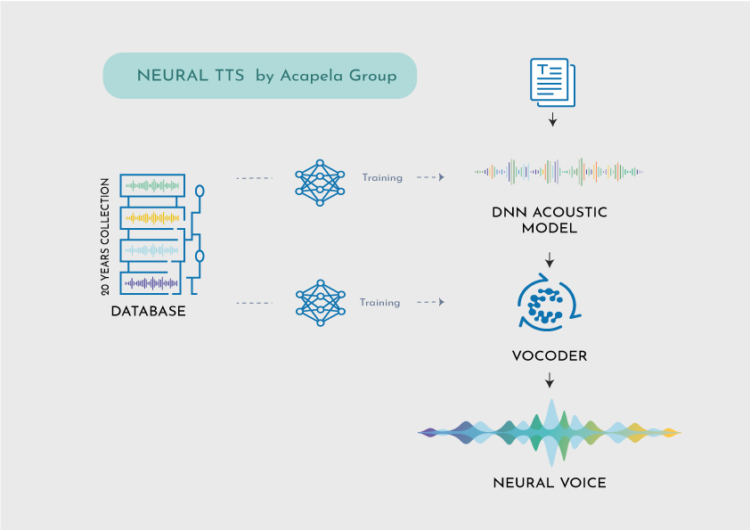
QU’EST-CE QUE LES DNN?
Les réseaux de neurones profonds (DNN) sont des réseaux neuronaux artificiels (ANN) avec de multiples couches cachées entre les couches d’entrée et de sortie.
Les réseaux neuronaux sont un ensemble d’algorithmes conçus pour reconnaître des modèles. Ils interprètent les données sensorielles par le biais d’une sorte de perception automatique, en étiquetant ou en regroupant les données brutes. Les modèles qu’ils reconnaissent sont numériques, dans lesquels toutes les données du monde réel (images, sons, textes) sont produites ou interprétées.
Les réseaux neuronaux profonds peuvent ainsi modéliser des relations non linéaires complexes à l’aide de technologies d’apprentissage automatique. Nous les utilisons dans la synthèse vocale pour apprendre la relation entre un ensemble de textes d’entrée et leurs réalisations acoustiques par différents locuteurs en sortie.
La synthèse neuronale peut être entraînée sur une grande quantité de données pour apprendre les schémas complexes de la parole humaine, tels que l’intonation, le rythme et l’accentuation et générer un résultat audio très naturel et expressif, qui ressemble de près à la parole humaine.
COMMENT CELA FONCTIONNE-T-IL?
Le DNN d’Acapela est entraîné hors ligne à l’aide de grandes infrastructures GPU. Il sait beaucoup de choses sur la parole humaine en général mais ne sait encore rien sur la voix d’une personne spécifique et aura besoin d’entendre cette voix pendant un certain temps pour pouvoir la reproduire.
- 1ère passe de l’algorithme : extraction des paramètres ‘Voice ID’ pour définir la signature numérique (ou sonorité) du conduit vocal du locuteur.
- 2ère passe de l’algorithme : Entraînement supplémentaire du DNN d’Acapela pour faire correspondre l’empreinte de la voix avec ses détails les plus fins (accents, habitudes d’élocution, etc.).
Acapela DNN bénéficie de l’expertise vocale Acapela pour modéliser les identités vocales et reproduire la parole. Cela va bien au-delà de la concaténation d’enregistrements vocaux provenant du studio, comme nous le faisions avec la sélection d’unités et les technologies précédentes, encore largement utilisées.
Dans des cas spécifiques tels que le remplacement de la voix des patients, Acapela DNN peut travailler avec quelques minutes de parole. C’est ce que nous réalisons pour les patients avec my-own-voice, une solution récompensée par le prix de l’innovation au CES 2023, qui permet aux personnes souffrant de troubles de la parole de continuer à parler avec une copie numérique de leur voix d’origine, sous forme de voix synthétique.
Pour un usage commercial, comme la création d’une voix-marque pour un constructeur automobile souhaitant guider les conducteurs de ses véhicules à une voix reconnaissable ou encore pour accompagner les passagers d’un opérateur de transport public dans leurs déplacements, davantage d’enregistrements seront nécessaires. Plus il y a de données, plus le DNN peut apprendre des habitudes spécifiques et créer une voix qui correspond à l’originale. Ces voix de grande qualité permettent de mettre en place des interactions naturelles, établissant ainsi une nouveau standard de qualité pour une expérience utilisateur réussie.
« Les premiers résultats des recherches menées en 2017 ont été impressionnants. Nous avons travaillé sur des enregistrements vocaux de personnes connues. Nous avons également créé des voix pour des personnes qui ne peuvent plus parler correctement en raison d’une opération chirurgicale ou d’une maladie. Elles ont été les premières à parler avec des voix créées avec Acapela DNN. La création de voix basée sur cette nouvelle technologie est sans limite. Acapela s’appuie pleinement sur la richesse de ses bases de données vocales et de son expertise acquise au fil des années pour repousser les limites de la technologie et permettre à chacun d’avoir une voix », ajoute Rémy Cadic, PDG d’Acapela Group.
Nous travaillons sur l’intégration des locuteurs (speaker embeddings) pour modéliser la voix. Nos modèles, entraînés sur de vastes ensembles de ressources vocales, capturent les principales caractéristiques de la langue parlée. Cette nouvelle technologie ouvre de vastes perspectives pour le marché du TTS et pour Acapela Group en permettant de développer plus rapidement des langues et des voix de belle qualité, pour plus de choix et de diversité pour tous.
Démo interactive
Testez les voix neuronales avec vos propres mots
Un peu d’histoire
L’histoire de la technologie TTS a commencé avec la toute première machine parlante (1779) créée par l’inventeur hongrois Wolfgang von Kempelen (…) Ensuite, les premières innnovations informatiques dès les années 50 par Bell Labs puis plus tard par IBM ont commencé à ouvrir la voie à la technologie de la parole. Les technologies des formants et des diphones ont apporté des améliorations majeures avant de passer à la sélection d’unités dans les années 90.
L’intelligence artificielle dessine aujourd’hui une nouvelle ère numérique avec les capacités d’apprentissage automatique et les voix neuronales. Chez Acapela Group, nous sommes profondément impliqués dans la technologie depuis 30 ans. Forts de nos décennies d’expertise et de nos précieuses connaissances linguistiques, nous créons des voix personnalisées qui font la différence, des voix accessibles à tous et qui ont du sens.
Vous avez besoin de plus d'informations pour votre projet ?
Book a demo